DynamoDB Streams
在dynamodb中数据的改变(update/delete/create),都可以到streams中。它对原表性能几乎没有影响。

stream中的数据会保留24h,假如当前关掉了dynamodb stream,数据会保留24h后失效。
lambda能够读取stream,于是可以实现以下场景:
- 实时处理(例如新用户注册,给用户发邮件)
- 实现跨区域数据同步。
- 插入到Elasticsearch
插入到Elasticsearch使用场景

想像有一个游戏业务,每秒钟都会开很多局。每条记录里有playerId, score信息,想统计出实时得分最高的前十名选手。
一个想法是:每一个小时扫一下全表,统计最近一个小时内,所有选手的分数之和。但这种不是实时的,且耗资源。
如果使用stream,实时将记录插入到elasticsearch,则可以查询出前N名。

在elasticsearch中,也可以灵活自定义各种查询方式:

stream类型
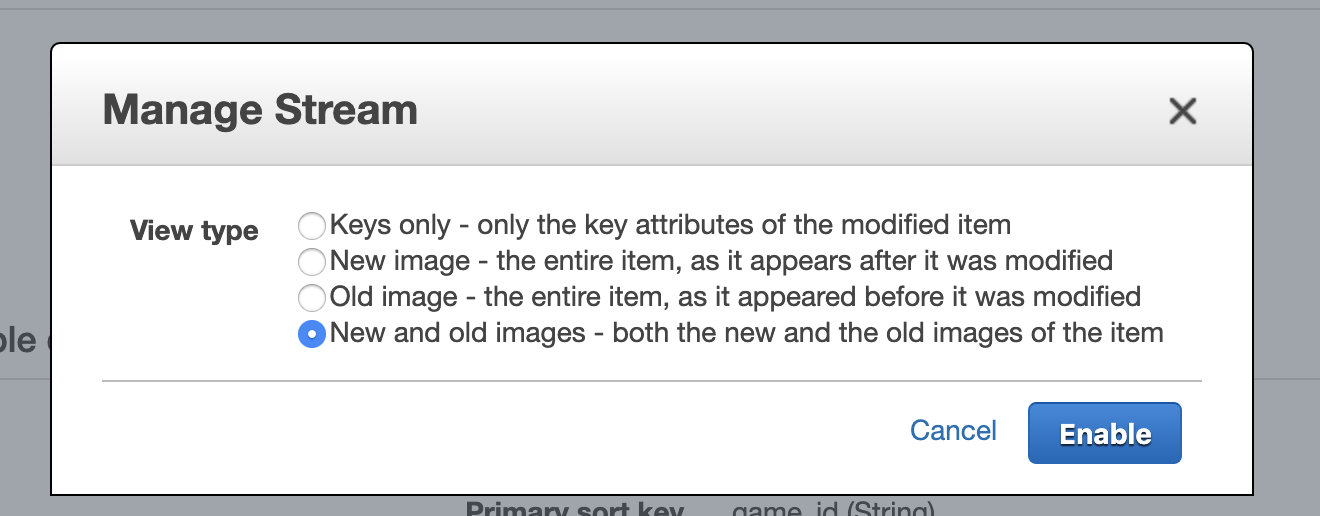
stream中,可以自定义存储哪些数据:
- Keys only — 只传被修改记录的key
- New image — 修改后的记录
- Old image — 修改前的记录
- New and old images — 修改前和修改后的记录 (最常用)
Lambda处理DynamoDB stream
Lambda 以每秒 4 次的基本速率轮询 DynamoDB stream中的分片以获取记录。当记录可用时,Lambda 会调用函数并等待结果。如果处理成功,Lambda 会恢复轮询,直到收到更多记录。

默认情况下,Lambda 会在记录可用时立即调用函数。如果 Lambda 从事件源读取的批处理中只有一条记录,则 Lambda 只会向该函数发送一条记录。为了避免在记录数量较少的情况下调用该函数,可以通过配置批处理窗口来告诉事件源缓冲记录最多 5 分钟。在调用该函数之前,Lambda 会继续从事件源读取记录,直到它收集了完整的批处理、批处理窗口到期或批处理达到 6 MB 的有效负载限制。
测试
首先要开启stream:

点击创建触发器。

在这里我们提前创建好了一个role,用于lambda访问dynamodb:


创建完成后,我们在dynamodb里刷新页面,可以看到对应的函数:

此时在user表里插入两条数据,然后删除一条,更新一条。
在cloudwatch里可以记录下详细的操作:
